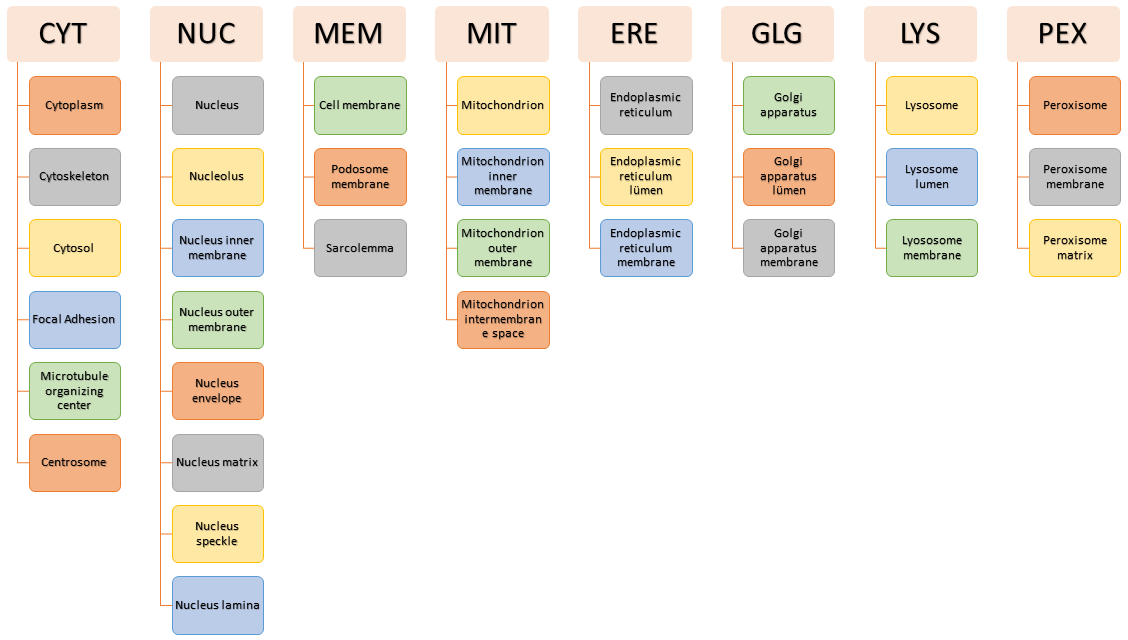
Datasets
We used three datasets for training and evaluation of SLPred. Trust dataset is our in-house dataset, composed of 4,431 human proteins, 35 unique SL terms, and 8,098 SL annotations, that is employed for the training (“trust-train” split), validation (10-fold cross-validation on “trust-train”), and testing (“trust-test”) of the method. Golden-dataset was constructed as a benchmark dataset by the developers of the SubCons tool (Salvatore et al., 2017), and composed of 1,226 human proteins and 3,306 annotations. Golden-trust dataset is the refined version of the golden dataset which is composed of 572 human proteins and 1,810 annotations. Here, we modified the golden dataset according to the procedure applied in constructing the trust-dataset on top of removing proteins that are in the trust-dataset. We used golden- and golden-trust datasets for the independent evaluation of SLPred and comparison with the state-of-the-art methods. You may download the datasets used in SLPred from here